A word version of this document can be found [here]
AGILE—an overview of achievements 1998-2000
AGILE stands for Automatic Generation of Instructions in Languages of Eastern Europe. Its aim was to develop a Natural Language Generation (NLG) system which can be used to produce user manuals for CAD-CAM systems in Bulgarian, Czech and Russian. A practical advantage of multilingual NLG systems is that an end user who knows only one language supported by the system can produce texts in all the available languages. This three-year project, which started in January 1998, involved the Bulgarian Academy of Sciences, Charles University in Prague, the Russian Research Institute for Artificial Intelligence, the University of the Saarland and the University of Brighton (coordinators).
The project built on the success of the DRAFTER system, developed by the ITRI with support from two commercial partners, Praetorius Ltd and Integral Solutions Ltd. DRAFTER stands for DRafting Assistant For TEchnical writers, and the system enabled the production of draft software manuals in English and in French. The research was funded by the UK Engineering and Physical Sciences Research Council (EPSRC) and completed in March 1997.
AGILE developed a prototype system which allows users to specify the content of the instructions for carrying out individual tasks in the CAD-CAM domain. This content is then automatically expressed in each of the three languages in parallel. The approach of multilingual NLG used in this project contrasts with the more conventional approach of Machine Translation (MT) in that the starting point is not a source text in one language, but a non-linguistic specification of the content to be expressed.
An innovative feature of the AGILE system is its ability to generate texts of several types and in two styles. The system can re-use the information already specified for a range of individual tasks in order to generate other sections of a typical software manual: a table of contents, informative overviews of the set of tasks, full instructions for each task, abbreviated instructions for each task, and functional descriptions of the interface objects used to perform them. Certain of the text types can be generated either in a personal style that addresses the reader directly, or in an impersonal style. The definition of these text types and styles was based on the analysis of representative corpora in all three languages.
Moreover, the AGILE project represents the first attempt ever at a computational account of Bulgarian, Czech and Russian for the purpose of natural language generation. These grammars are implemented in the Komet-Penman MultiLingual (KPML) environment.
The output of the AGILE document generator—an illustration in English
Here are examples—in English, for generality of illustration—of some different text types generated in the personal style.
Full Instructions
To draw an arc
First start the ARC command using one of these methods:
Windows: From the Arc flyout on the Draw toolbar, choose 3 Points.
DOS and UNIX: From the Draw menu choose Arc. Then choose 3 Points.
Now specify three points of the arc.
1. Specify the start point (of the arc). First enter endp. Then select a line. The arc snaps to the endpoint of the line.
2. Specify the second point of the arc. First enter poi. Then select a point. The arc snaps to the point.
3. Specify the endpoint of the arc.
The system has flexible strategies for deciding whether to express a given ‘package’ of information into several sentences, as above, or into a single sentence, as below.
…
Now specify three points of the arc.
1. Specify the start point of the arc by entering endp and selecting a line so that the arc snaps to the endpoint of the line.
…
Overviews
Overviews provide a summary of all the tasks that are documented inn the manual. They can be more or less randomly ordered, as here.
The system
enables you to create a multiline style, to specify the properties of a multiline, to draw a
line and arc combination polyline, and to draw an arc by specifying three points.
Alternatively, the tasks can be grouped according to the objects the user can act upon—e.g. ‘multiline’—or the actions the user can perform—e.g. ‘draw’.
The system
enables you to create a multiline style, and to specify the
properties of a multiline. You may also draw a line and arc combination
polyline, and an arc by specifying three points.
Functional Descriptions
These describe the functionality of user interface commands such as buttons in toolbars or dialog boxes. The descriptions can be organised according to the identity of the command.
The Polyline button on the Polyline flyout from the Draw toolbar (under Windows) starts the PLINE command.
The Polyline button on the Draw menu (under DOS and UNIX) starts the PLINE command.
Alternatively, the descriptions can be expressed in terms of the action the user must perform.
Selecting Add in the Element Properties dialog box adds an element.
Choosing OK in the Element Properties dialog box saves the style of the multiline element and exits the Element Properties dialog box.
The input to the AGILE document generator
The person—usually a CAD-CAM system
designer—who is providing the information to be expressed in the manual
proceeds by creating ‘models’ of individual user tasks. The task model is built up in the form of nested boxes which mirror
the GOAL + METHOD structure of software instructions (Figure 1). Clicking on a slot in a box brings up a menu of
available fillers—actions or objects, depending on the nature of the slot.
Let us assume that the technical author wants to build a task model describing the procedure of drawing a line by defining its start and end points. Thus, the GOAL is draw and the METHOD is specify end points, and the author will select draw from the choices shown in Figure 1.
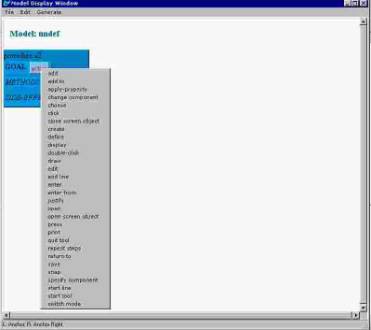
Figure 1. Specifying the GOAL action
Next, the author must specify what is to be drawn (Figure 2). The fact that this slot must be filled is signalled by the red label. The context-sensitive menu will display only the names of those objects that can be drawn using the CAD-CAM application, e.g. arc and polyline, but not UNIX or menu.
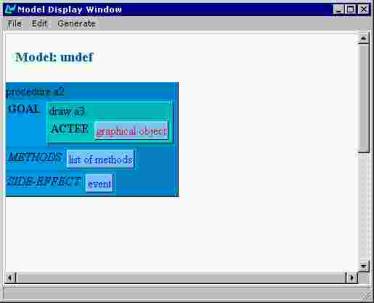
Figure 2. Specifying the GOAL object
Figure 3 shows the task model on the point of completion. The author has fully specified the GOAL and the first STEP in the METHOD—defining the start point. The action of the second step—define—has also been specified and all that remains is to select the object—end point.
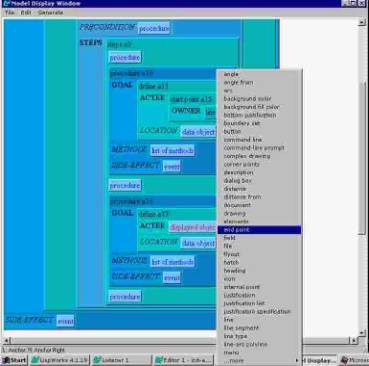
Figure 3. Choosing a value to complete the model
Selection of text type and style
Once the task model has been completed and saved, the author can choose in which languages and styles to have its content expressed (Figure 4). The ‘Overview’ option applies only when the author chooses to generate the documentation for several tasks at the same time. This corresponds to producing a section or chapter of a manual. In these conditions, the table of contents is generated automatically.
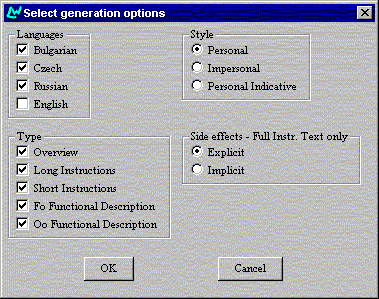
Figure 4. Selecting languages, text types and styles
Display of the output
The generated HTML documents are displayed in a browser window (Figure 5). A separate window is opened for each output language. The pane on the left contains the list of contents, represented by hyperlinks to the corresponding sections of the manual displayed in the pane on the right. The documents can be saved and edited as required.
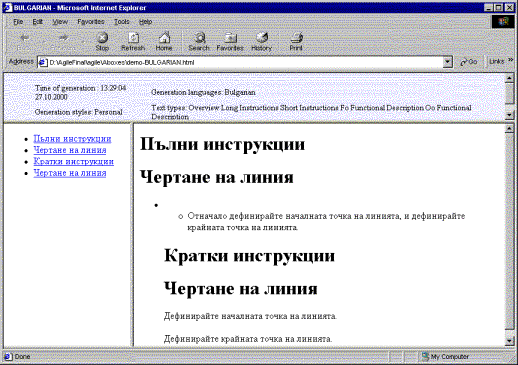
Figure 5. Generated text in Bulgarian.
Planning texts of different types and styles
Our analysis of the corpora of instructional texts collected for each language revealed marked differences between languages in the ways in which the same content is expressed. One of the advantages of multilingual NLG over MT is that the style of the output text can be made fully appropriate to the target language, with no interference from structures more appropriate to some other (source) language. In the AGILE project, we aimed to produce texts that are sensitive to the stylistic requirements of not only the output language, but also the various sections of the manual. For example, the full instructions section can be generated in either a personal or impersonal style. In the former, the reader (software user) is addressed directly; in the latter, the tone is more formal.
A
text planner, or Text Structuring Module (TSM), is responsible for constructing
a text plan that matches the genre and style features selected by the ‘author’
to the information that she has specified via the graphical interface; the plan
structures the information accordingly. A sentence planner then interprets the text plan to create plans for
sentences, each of which expresses a piece of information identified by
elements of the text plan. By generating a sequence of sentence plans, and
having a lexico-grammar generate each one as it comes, AGILE produces the
entire text that expresses the content specified by the user.
The TSM’s approach to discourse structuring combines elements of Halliday's Systemic Functional Grammar (SFG), Mann and Thompson's Rhetorical Structure Theory (RST), and the Prague Functional Generative Description (FGD). Importantly for the three Slavic languages represented in AGILE, the TSM is able to reflect textual (information) structure through contextually appropriate word order. The synthesis of the three approaches resulted in a design that adds value over and above the contributions made by each individual approach.
Developing unified grammars for Bulgarian, Czech and Russian
Our approach
Achieving the project goals meant developing for all three languages text grammars, sentence grammars and dictionaries that are specially designed for the purposes of NLG. Since the process of NLG is not simply the reverse of the process of Natural Language Understanding (NLU), re-purposing existing NLU resources for these languages was not a viable option. So grammar development had essentially to start from scratch.
We developed new computational grammars of each of the languages of study. The approach taken for this was to re-use a large-scale, broad coverage English grammar (KPML: Komet Penman Multilingual) in order to construct grammars of a similar scale for Bulgarian, Czech and Russian. The priorities for grammar development were set by a corpus-based contrastive analysis of (non-translated) instructional texts in the target languages. This resulted in the creation of sub-language grammars for the domain.
If the production of NLG resources for the project languages is itself novel, the approach to grammar development is even more so. Rather than writing separate grammars for Bulgarian, Czech and Russian, the partners developed a unified grammar which captures the 'common core' of the three languages and, as a complement, the points where one language diverges from the other two or all three go their separate ways. The gains in computational efficiency may not be great. In contrast, this approach significantly increases the theoretical interest of the project. You would naturally expect the three languages to share many features by virtue of their common Slavic origins. But what is also striking is the extent to which they share features with the English grammar ‘platform’ which underpins the Slavic grammar development.
Figure 6, Figure
7 and Figure
8 illustrate for each language the grammatical
structure underlying the sentence equivalent to Enter the ‘Draw’ command and
click on the ‘OK’ button to start the program.
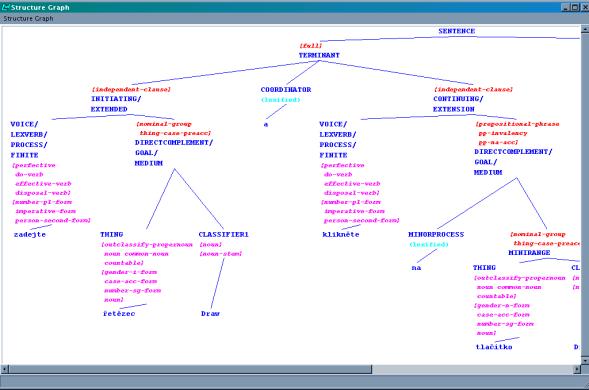
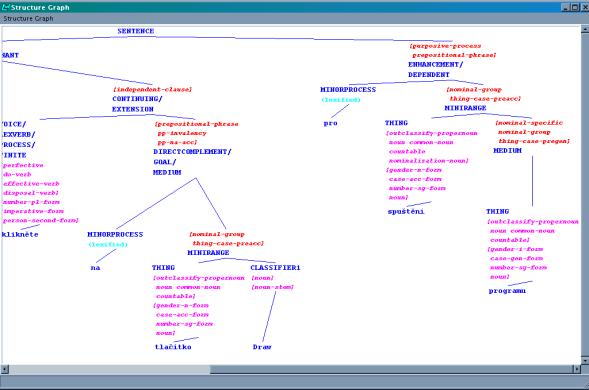
Figure 6: Grammatical structure for Czech
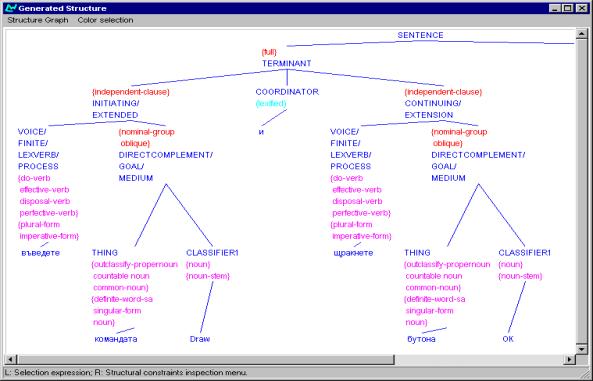
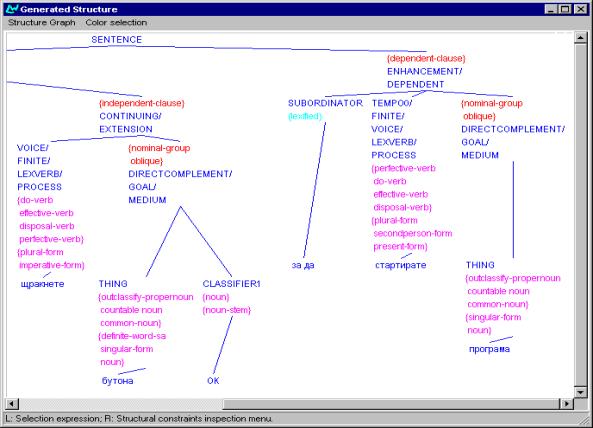
Figure 7: Grammatical structure for Bulgarian
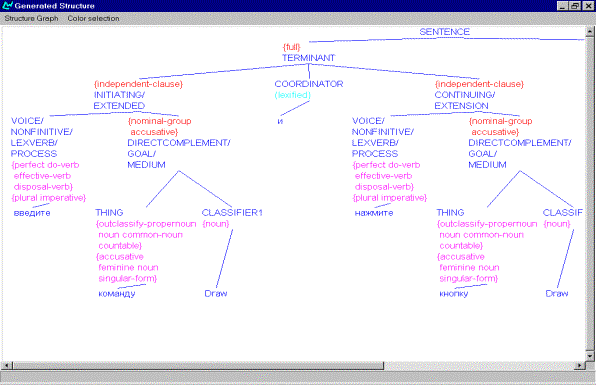
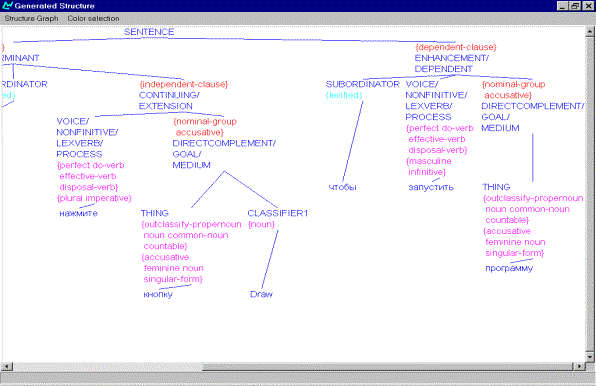
Figure 8: Grammatical structure for Russian
The KPML environment for grammar development
A primary goal of the AGILE project was to develop lexico-grammatical resources suitable for multilingual generation. Indeed, this project represents the first attempt ever at a computational account of Bulgarian, Czech and Russian for the purpose of natural language generation. The size and complexity of this task made us consider especially carefully the question of which computational linguistic framework to choose for resource development.
We were looking for a framework that would be: accessible to the partners in terms of the linguistic concepts it used; adaptable to the project languages; and interfaceable with other components of the complete application. These requirements led us to opt for KPML.
KPML is based on a functional theory of language, Systemic Functional Grammar, a linguistic approach that shares many of its characteristics with the Eastern European tradition of functional linguistics. KPML is especially geared towards the development of multilingual grammars, and offers various ways of sharing the computational description of an existing grammar with new languages that are added to the system. Also, it supports a truly contrastive-linguistic way of building up multilingual resources for new languages, such as merging grammars of different languages into one resource or writing out grammars of individual languages from a common resource. KPML is also a well-established tactical generator, which has been used in numerous generation projects where it has been interfaced with a variety of other computational linguistic components, notably text planners and domain models. Since KPML is built on general linguistic principles, it was possible in AGILE to use it for modelling part of the text planning resources, thus providing a natural connection between the grammar and text structure.
Evaluating the AGILE system
Compared with Natural Language Understanding, Natural Language Generation is a field where little previous work had been done on evaluation, particularly of end-to-end systems that go all the way from content specification to text generation. Researchers have tended to highlight the complexity and difficulty of the task, but were able to draw on our experience of evaluating DRAFTER.
For
AGILE, we designed an evaluation scenario which addressed: the usability
of the integrated system for creating and editing text specification models;
and two dimensions of text quality—the grammaticality of the output
texts their acceptability as a first draft of a user manual. We paid
particular attention to the appropriateness of the different text types and
styles available to the user.
The results of our evaluation showed that, with training, users are able to write documentation for the CAD/CAM domain in their own language with the aid of AGILE and that the quality of output texts is sufficiently good for their inclusion into drafts of high-quality manuals. This was true for all three localised versions and for all the subjects tested. However, the system interface proved to be cumbersome to use and to be unintuitive in places.
Usability
The
evaluators were, at each site, IT specialists rather than authors or linguists.
The evaluation proper was preceded by in-depth training—both in the underlying
concepts and in the use of the system itself. To support, this we created a
Conceptual Tutorial, which introduces basic concepts of authoring documents in AGILE, and a Training Manual,
which defines methods for specification of a fragment of a manual in close
resemblance to real authoring conditions.
The
testing session comprised five exercises, each of which had a time limit. The evaluators were asked to edit and
create both simple and complex models for individual CAD-CAM tasks, and to
compose sets of models for related tasks. Partially built models were sent from
one site to another for completion.
The knowledge editing interface was judged to
be rather clumsy. Detailed analysis of the task models produced by the
evaluators showed that the most of them were correctly structured. But in some
cases evaluators had wrongly created multiple instances of a concept instead of
multiple pointers to a single instance. of them had failed to make multiple
references to a single concept.
Acceptability
The evaluators were native speakers of the language they judged, and experienced in writing and/or translating software documentation. Following methods used to evaluate machine translation systems, they were asked to rate the quality of the output on a four-point scale—Excellent, Good, Poor, Terrible. They also rated the Full Instructions relative to human-authored reference texts.
The texts generated by AGILE in all three languages were judged to be of comparable quality to similar texts found in good commercial manuals. Functional Descriptions, Full Instructions and Quick References were judged Good to Excellent, while Overviews, were rated Poor to Good.
Grammaticality
For each of the three languages, we obtained judgments from two native speakers trained in the linguistic description of their own language. In order to keep the content constant across the three languages, the six judges were asked to evaluate texts which originated from one and the same composite task model.
Their evaluations covered all of the running-text types, using 16 error categories. For Bulgarian and Russian, these text types were made available in two stylistic variants: Personal and Impersonal. Since Czech has two ways of expressing personal style, the Czech judges evaluated three variants: Personal Indicative, Personal Explicit and Impersonal Explicit.
Almost no grammatical errors were identified by the judges, other than errors classified as ones of word order, a well-known difficulty in Eastern European languages. Even then, some were thought to be stylistic rather than syntactic.
Coverage
We employed a method of grammar development
that was both instance-oriented and system-oriented. Instance-oriented means basing development on a corpus of
texts from the target sublanguage. System-oriented means building the
computational grammar with a view to the language system as a whole, an
approach which flows naturally from Systemic Functional Grammar’s inherent
property of considering whole grammatical paradigms rather than just fragments.
Moreover, KPML is organized according to functional regions which group
individual grammatical systems into larger classes.
We therefore assessed the extent to which the multilingual resources developed within the project cover those grammatical constructions found at four increasingly general levels: the texts extracted from CAD/CAM manuals that served as a ‘target’ for the AGILE prototype; software manuals in general; other instructions; and general language.
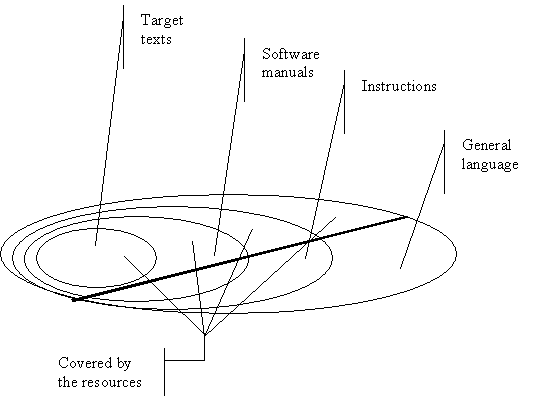
Figure 9 Coverage of lexico-grammatical resources
These resources cover a significant proportion
of the general language, although there remain gaps in coverage (negation, for
example). The development of certain constructions was impeded by the inability
to represent their semantics in the Domain Model, which for AGILE is an
ontology of concepts from the CAD-CAM domain.
The official verdict on AGILE
This is how the Tomaž Erjavec summarized his assessment of AGILE in his official review for the European Commission.
AGILE
has successfully addressed the INCO-COPERNICUS call objectives, in particular
to transfer expertise in language engineering (text generation) from EU
partners to CEE countries and languages, and provide significant and harmonised
language tools and resources for these languages. AGILE has, taking into
account that it was at the time of review still ongoing, delivered according to
its work programme. The deliverable quality is consistently good, with
substantive project reports (also available on the AGILE Web site), and a
working demonstrator.
The
results of AGILE exhibit a significant added value due to work having been
closely harmonised for the three languages involved. It is in the production of
harmonised language generation resources for three Slavic languages that I see
the main contribution of the project. The value of the achieved results would
have been even greater, were the English and French generation modules also
included in the extended AGILE generator; in the event, it seems budgetary
restrictions made it infeasible to include this in the project work-plan. The
project has made original contributions in other areas. It has developed an
assessment protocol, used in the evaluation of the prototype generator; the
demonstrator has the ability to generate more than one type of text from a
given semantic representation. One area where the project could have had more
impact is the standardisation of linguistic resources and software. This is a
very active area; in resource standardisation, TEI has given the initial
impetus, with a number of EU projects (esp. Eagles) making further effort in
this aspect of reusability. In my opinion, EU projects should be pro-active in
the adoption of standardised and open solutions in encoding of linguistic
information; this means, inter-alia, using standard (ISO) character set
encodings, ISO abbreviations for names of languages, and HTML/PDF for report
presentation. More challenging, and a topic of great interest, would be the
adoption of SGML and/or XML for encoding of the linguistic resources and
language models in AGILE.
User
involvement and market viability were stated project objectives but suffered
from the withdrawal of industrial partner. However, the Copernicus call was
aimed more at language infrastructure development, in which context it is more
difficult to attain immediate exploitability. In fact, the project spent rather
too much effort on visual interfaces for the prototype, where extending further
the language models could lead to more lasting benefits. In lieu of user base,
the project incorporated extensive assessments, thus advancing the state-of-art
in this area.
AGILE
was well managed, with problems having been successfully resolved within the
life-time of the project. The problems encountered to a large extent
accompanied most Copernicus project, where some partners had limited experience
with international projects, and where organisational and economic structures
and differences make project coordination and harmonisation of results a very
difficult task, for all the involved partners. AGILE successfully coped with
these problems by e.g. a concentrated effort of meetings and workshops. An area
where coordination could have been more extensive is in liaising with other
projects, esp. those also involving ITRI and falling under the Copernicus
programme, i.e. Concede and, indirectly, MULTEXT-East.
The
project very soon developed a WWW and email based platform of AGILE-internal
communication and dissemination. This encouraged modern practices in
collaborative work, and seems to have helped to arrive at better and more
consistent results.
The
dissemination and promotion activities are well in place, with the public
project Web site, and an increasing number of publications for each year of the
project.